If we focus on RAID’s status in the present day, some RAID levels are certainly more relevant than others. RAID 5 specifically has been one of the most popular RAID versions for the last two decades. As disk sizes have increased exponentially, it does beg the question, though; is RAID 5 still reliable? To answer this question, we’ll first have to talk about what RAID 5 exactly is, it’s working mechanisms, applications, and flaws.
RAID Terminology
RAID 5 uses block-interleaved distributed parity. To understand this, we’ll have to start with the basics of RAID. Redundant Array of Independent Disks (RAID) is basically data storage technology that’s used to provide protection against disk failure through data redundancy or fault tolerance while also improving overall disk performance. RAID systems implement techniques like striping, mirroring, and parity. Striping spreads chunks of logically sequential data across all the disks in an array which results in better read-write performance. Parity, in the context of RAID, is recovery data that is written to a dedicated parity disk or spread across all disks in the array. If a disk in the array fails, this parity data, along with the data on the remaining working drives, can be used to reconstruct the lost data.
How Does RAID 5 Work?
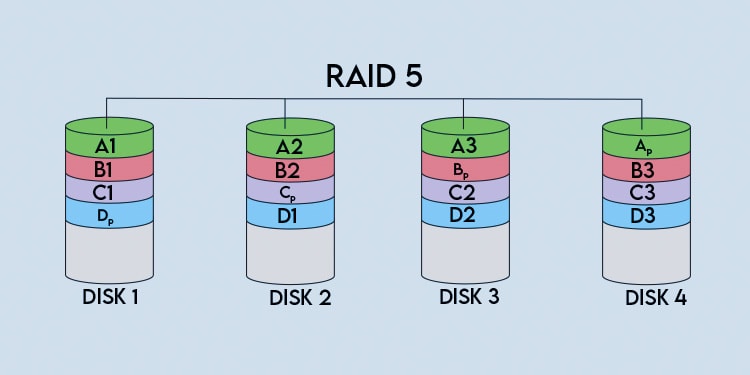
RAID 5 arrays use block-level striping with distributed parity. As atleast two disks are required for striping, and one more disk worth of space is needed for parity, RAID 5 arrays need at least 3 disks. Let’s take a 4-disk RAID 5 array as an example to understand better how it works. When writing to the array, a block-sized chunk of data (A1) is written to the first disk. This chunk of data is also referred to as a strip. The size of the block is called the chunk size, and its value varies as it’s up to the user to set. Continuing with the write operation, the next logically consecutive chunk of data (A2) is written to the second disk and the same with the third (A3). As data blocks are spread across these three strips, they’re collectively referred to as a stripe. Stripe size, as the name implies, refers to the sum of the size of all the strips or chunks in the stripe. Generally, hardware RAID controllers use stripe size, but some RAID implementations also use chunk size. Continuing again, after data is striped across the disks (A1, A2, A3), parity data is calculated and stored as a block-sized chunk on the remaining disk (Ap). With this, one full stripe of data has been written. In our example, the same process repeats again as data is striped across three disks while the fourth disk stores parity data. To put it simply, this continues until the write operation completes. But there are some more things to cover here, such as how parity data is actually calculated and the layout of data and parity blocks in the array. So, let’s shift the focus to those in the next section.
Parity In RAID 5
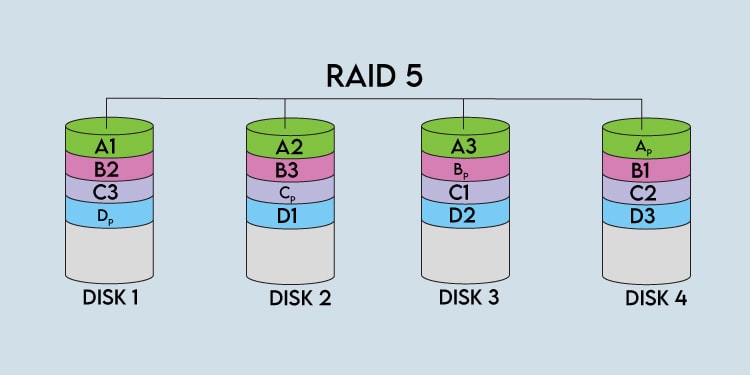
Different RAID levels use different algorithms to calculate parity data. RAID 5 specifically uses the Exclusive OR (XOR) operator on each byte of data. XOR returns a true output when only one of the inputs is true. If both of the inputs are true (1,1) or false (0,0), the output will be false. The table below and the example that follows should illustrate this better. Let’s go back to our example from earlier and look at the first stripe. Let’s say the first byte of data on the strips is as follows: A1 – 10111001A2 – 11001010A3 – 10011011 By performing an A1 XOR A2 operation, we get the 01110011 output. When we perform another XOR operation with this output and A3, we get the parity data (Ap) which comes out to 11101000. Let’s say one of the disks in the array (e.g., Disk 2) fails. We can perform an A1 XOR A3 operation to get 00100010 as the output. If we perform another XOR operation with this output and the parity data, we get the following output: 001000101110100011001010 With this, we’ve reconstructed the first byte of data on Disk 2. And this, in a nutshell, is how parity data provides fault tolerance and protects your data in case of disk failure. This redundancy does have its limits, though, as RAID 5 only protects against one disk failure. If two disks fail simultaneously, all the data will be lost. Finally, there’s also the matter of data layout in the array. Unlike RAID levels 2, 3, and 4, which use a dedicated parity disk, RAID 5 uses distributed parity. This means the parity blocks are spread across the array instead of being stored on a single drive. Our example from earlier shows a left-to-right asynchronous layout, but this can change depending on certain factors. For instance, the data blocks can be written from left to right or right to left in the array. Accordingly, the parity block may be located at the start or end of the stripe. In the case of a synchronous layout, the location of the parity block also determines where the next stripe will start. For instance, the array below is set up as left synchronous, meaning data is written left to right. Additionally, the parity block (Ap) determines where the next stripe (B1) starts, and so on.
Should You Use RAID 5?
RAID 5 provides both performance gains through striping and fault tolerance through parity. And unlike lower RAID levels, it doesn’t have to deal with the bottleneck of a dedicated parity disk. This made it very popular in the 2000s, particularly in production environments. However, RAID 5 has always had one critical flaw in that it only protects against a single disk failure. In theory, two disks failing in succession is extremely unlikely. But during real-world applications, things are different. For starters, HDD sizes have grown exponentially, while read/write speeds haven’t seen great improvements. Due to this disparity, when a disk does fail, rebuilding the array takes quite long. Depending on the size and specs of the array, this can range from hours to days. Next, people often buy disks in sets. When you expose the same make drives to the same workload and environment, the chances of them failing around the same time increase. But let’s say only one disk failed. If you’ve regularly been disk scrubbing, you’re probably good. But if you haven’t been checking for errors, there’s a risk of encountering UREs during the rebuilding process, as one of the disks in the array has failed just now. Unrecoverable Read Errors (UREs) are a major issue when rebuilding arrays because a single MB of unreadable data can render the entire array useless. This is due to the way most RAID setups work. Certain RAID implementations like ZFS RAID and Linux software RAID and some hardware controllers mark the sector as bad and continue rebuilding. However, most hardware RAID controllers simply stop the reconstruction and mark the entire array as failed. The reasoning for this is that it’s best to stop the array rather than risk data corruption. This is done with the assumption that you’ll either restore from a backup or recover the data from each drive individually. When you combine all these factors, it’s not hard to see why RAID 5 has fallen out of favor in recent years. This is why other RAID versions like RAID 6 or ZFS RAID-Z2 are preferred these days, particularly for larger arrays, where the rebuild times are higher, and there’s a chance of losing more data. That’s not to say RAID 5 is already irrelevant, though. HDD manufacturers have taken these things into consideration and improved the drives by lowering URE occurrence rates exponentially in recent years. We recommend that you generally opt for other RAID levels, but if you want to go with RAID 5 anyway, you should only do so in the case of small-sized arrays. Finally, here are some requirements and things worth knowing if you plan to set up a RAID 5 array:
As mentioned earlier, a RAID 5 array requires 3 disk units at the minimum. This is because atleast 2 drives are required for striping, and one more disk worth of space is needed to store parity data.The usable storage in a RAID 5 setup can be calculated with (N – 1) x (Smallest disk size). You should use same-size drives because if you use an uneven setup, the smallest disk will create a significant bottleneck.RAID 5 provides excellent read performance as striping allows data to be read from multiple disks at the same time. However, by the same token, write performance isn’t as great as parity information for multiple disks also needs to be written.RAID 5 can be set up through software implementations, but it’s best to use hardware RAID controllers for a RAID 5 array as the performance suffers with software implementations.Finally, RAID’s redundancy is not the same thing as backups. RAID’s purpose is simply to protect against disk failure. There are plenty of reasons to have separate offsite backups, from malware to human error and accidents.